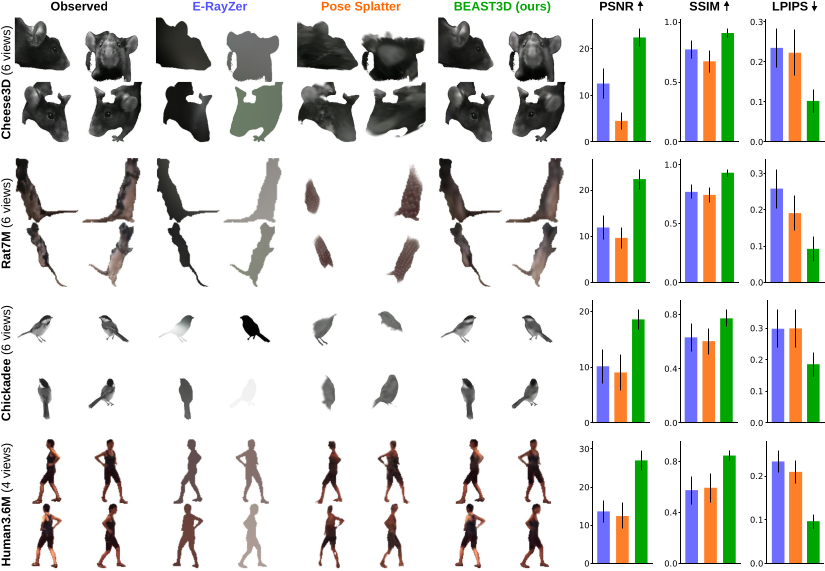
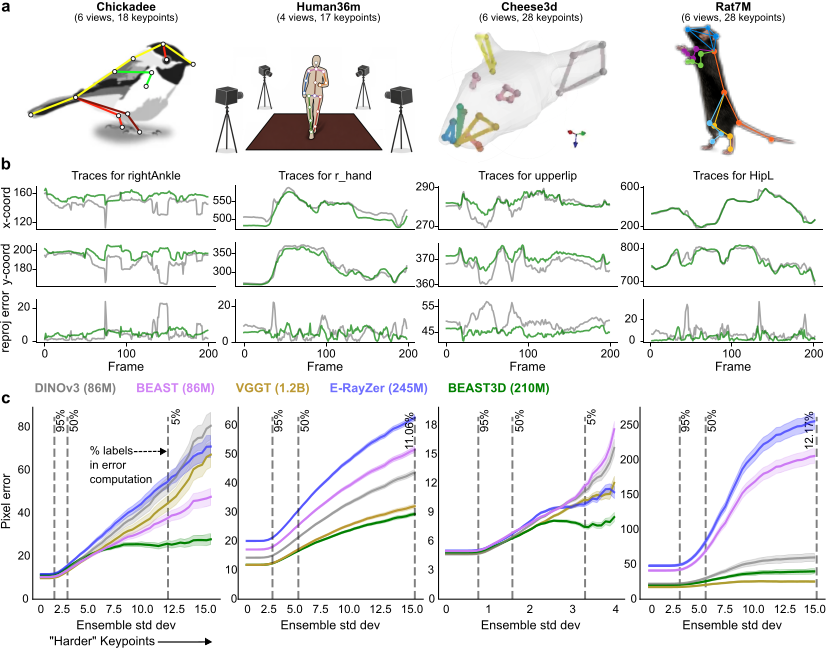
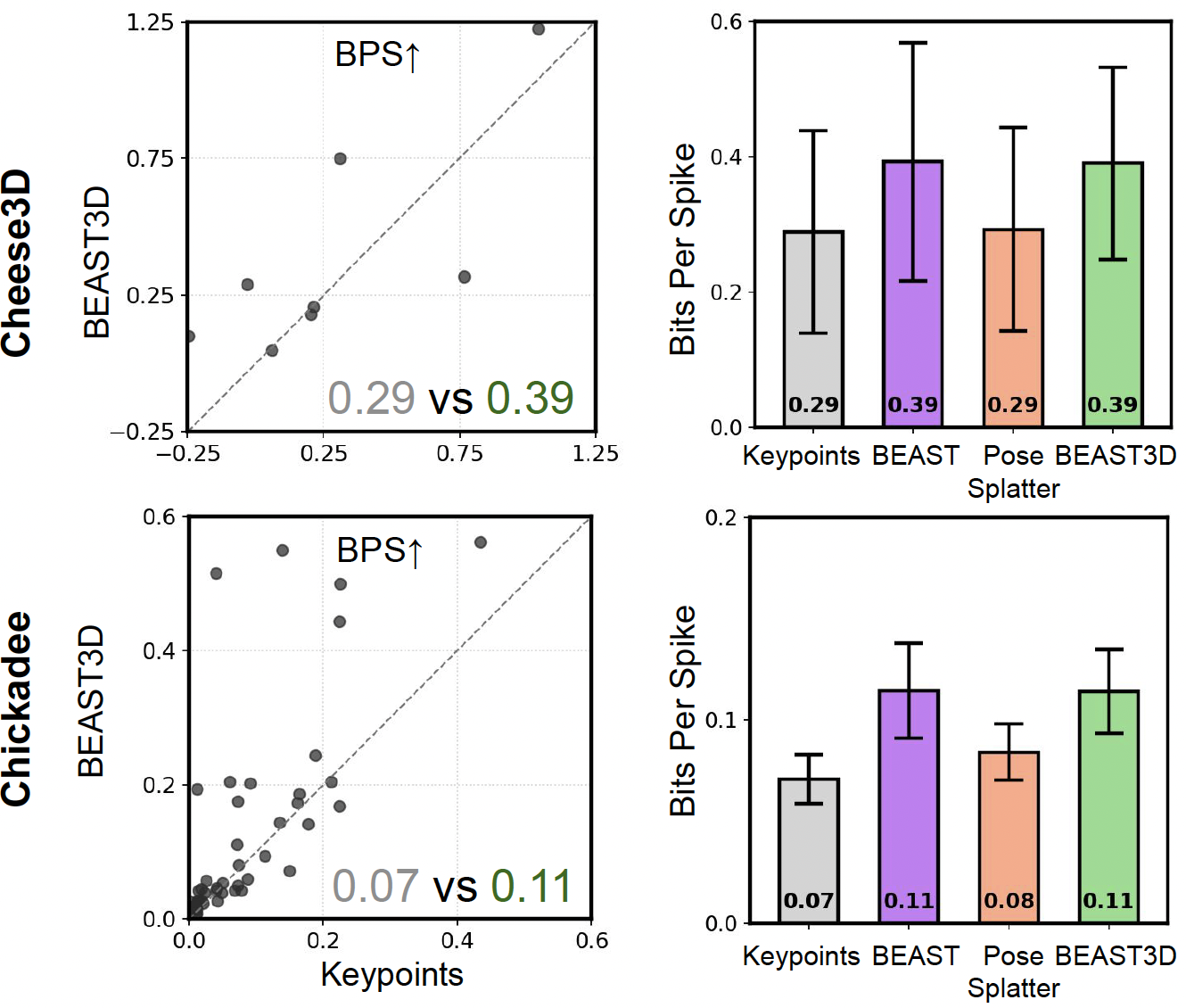
How BEAST3D works
BEAST3D is a masked autoencoder with 3D Gaussian splats as its intermediate representation. At each training step, one view is held out and reconstructed from the remaining views, so the model must infer real 3D structure rather than memorize 2D appearance. It conditions on known camera calibration and uses a frozen DINOv3 encoder, focusing its capacity on the subject's geometry and appearance.
Multi-view input & masks
Synchronized, calibrated views feed the model. SAM3 segmentation masks are computed once offline and distilled into the model — no segmentation network is needed at inference.
Per-view features & rays
A frozen DINOv3 ViT-B/16 tokenizes each view; per-pixel camera rays are encoded as Plücker coordinates and fused with the image tokens to ground them geometrically.
Geometry transformer → Gaussians
A VGGT-pretrained transformer alternates per-frame and global attention across views; a linear head decodes each patch token into a 3D Gaussian splat.
Differentiable rendering
GSplat renders the held-out target views. Photometric, perceptual, and mask losses on those views train the whole pipeline self-supervised.
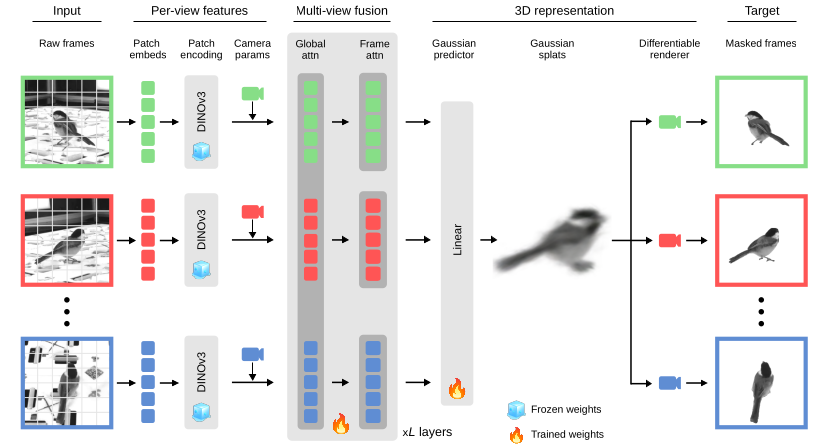
The BEAST3D framework. Reference views are tokenized by a frozen DINOv3 encoder and combined with camera-ray tokens, fused by a VGGT geometry transformer (frozen + trained weights), and decoded into 3D Gaussian splats. A differentiable renderer reconstructs masked target views; only the held-out views supply the training signal.